LLMs.txt: The Complete Guide to Making Your Site AI-Readable

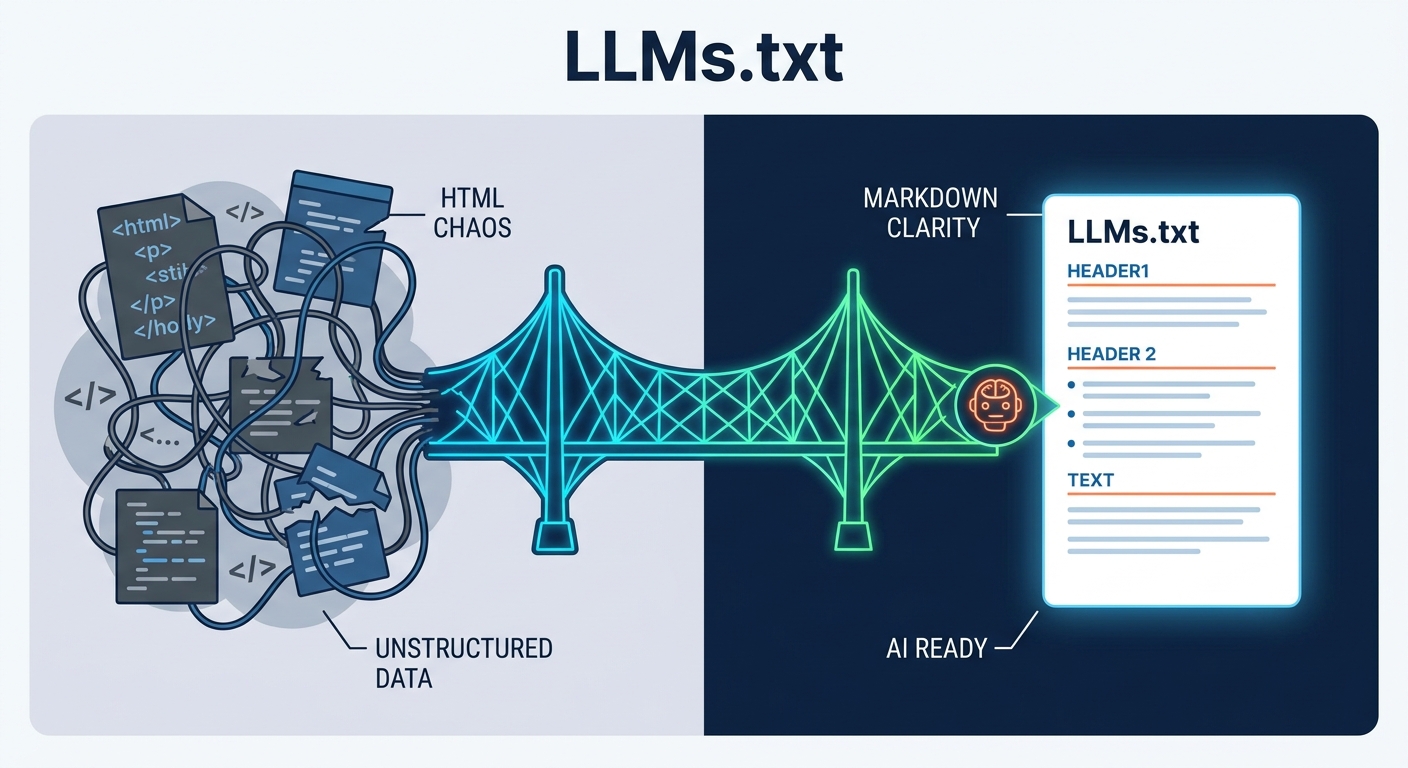
If you want your website to survive the transition from a human-browsed internet to an agent-driven one, you need to start speaking the language of machines. llms.txt is the bridge between your chaotic, bloated HTML architecture and the clean, structured data that AI models like Claude, ChatGPT, and Perplexity crave. By dropping a simple, Markdown-formatted text file at your root directory, you are no longer just hoping an AI understands your business—you are handing it a map to the treasure.
For years, we obsessed over "Search Engine Optimization"—stuffing keywords into headers and chasing backlinks to appease Google’s opaque, ever-shifting algorithms. But the era of the "ten blue links" is fading. Today, users ask an AI agent, "How do I integrate Stripe’s API for recurring billing?" and the agent doesn't visit a SERP; it visits the documentation directly. If your site is a tangled mess of JavaScript-heavy components and nested div-soup, the agent will struggle to parse your value. It will hallucinate, or worse, it will ignore you entirely. llms.txt is the frontier of AI-Agent discovery, providing a verifiable context layer that turns your site into a primary source, rather than a mystery for a crawler to solve.
What is an LLMs.txt file and how does it work?
At its core, an llms.txt file is an invitation. It is a plain-text file, formatted in Markdown, that sits at the root of your domain. It tells an AI agent exactly what is important on your site. Think of it as a table of contents for your brain. Instead of forcing a language model to guess what your navigation bar means or to click through dozens of pages, you provide a single, clean file that lists your core documentation, API references, and product guides in a format that LLMs digest natively.
The philosophy here is "AI-First" design. LLMs are trained on vast datasets of Markdown—it is the lingua franca of developers and documentation. When you serve your content in Markdown, you bypass the "noise" of modern web development—the sidebars, the tracking scripts, the CSS animations, and the cluttered footers that confuse agents. By aligning with the Official LLMs.txt Specification, you ensure that your site is not just accessible, but easily consumable.
Should you use llms.txt or llms-full.txt?
Implementation is not one-size-fits-all. You have to choose your level of commitment based on the complexity of your site and the "AI-readiness" of your existing content.
The "Light" approach is the standard for most businesses. It acts as a curated signpost. You provide a concise list of links to your most critical pages—your pricing, your core product features, and your primary documentation entry points. It’s a high-level summary that allows an agent to decide if your site contains the information it needs before it starts a deeper crawl.
The "Full" approach, or llms-full.txt, is for the heavy hitters. If you run a massive technical knowledge base or a complex API suite, this file becomes the payload. It contains the actual documentation text, not just links. This allows the AI to "memorize" your entire product architecture in one go. However, this requires your site to be surgically clean. If you aren't sure if your content is ready for this level of exposure, an AI-Ready Content Audit can help you identify which parts of your site should be exposed and which should be kept behind the curtain.
Here is a simple template to get you started:
# My Product Documentation
Welcome to our AI-ready knowledge base.
## Core Services
- [Product Overview](/docs/overview)
- [API Reference](/docs/api)
- [Pricing Model](/pricing)
## Guides
- [Quickstart Guide](/docs/quickstart)
- [Troubleshooting](/docs/faq)
Does Google care about your LLMs.txt file?
It is vital to draw a line in the sand: llms.txt is not for Google Search. If you are doing this because you think it will boost your domain authority on search engine result pages, you are mistaken. This is an protocol for the generative web. It is for the agents that are actively synthesizing information, not the crawlers that are indexing it for a list of links.
Skeptics point out that major AI labs haven't issued a "stamp of approval" for this protocol. They haven't added it to their official documentation as a mandatory signal. But that misses the point of competitive advantage. According to BuiltWith Tracking Data, over 844,000 domains have already adopted the format. These early adopters aren't waiting for permission; they are future-proofing their presence in the context windows of the world’s most powerful models. When an agent is deciding which source to cite in a response, it will naturally gravitate toward the site that is easiest to parse.
Who is doing it right?
The best way to learn is to look at the industry leaders who have already perfected the craft. Stripe’s llms.txt Example is widely considered the gold standard. It is clean, it is hierarchical, and it is brutally efficient. There is no fluff. It tells the agent exactly what the Stripe ecosystem looks like, what the API endpoints are, and how to navigate the documentation. They treat their content as a product, and their llms.txt file as the API to that product.
When you compare this to a standard, bloated HTML page—where an AI has to strip away thousands of lines of JavaScript and CSS just to find the actual documentation—the difference is night and day. A clean Markdown file is like a spotlight in a dark room; it guides the AI directly to the signal, ignoring the noise that clutters the rest of the web.
Is LLMs.txt the end-game or a stepping stone to MCP?
While llms.txt is the current standard for AI visibility, it is likely a stepping stone. We are already seeing the emergence of the Model Context Protocol (MCP), which promises a more robust, two-way communication channel between your site and an AI agent. Where llms.txt is a static "read-only" signpost, MCP is a dynamic, persistent connection.
Think of it this way: llms.txt is how you get in the door. MCP is how you hold a conversation. As we move deeper into 2026, the focus will shift from simply being "readable" to being "interactive." If you want to stay ahead of this curve, start by implementing your llms.txt today, and keep a close watch on your SEO Strategy Dashboard to see how your site’s visibility evolves in AI-driven answers compared to traditional search. The goal isn't just to be found; it’s to be understood.
Frequently Asked Questions
Is llms.txt a replacement for robots.txt?
No. robots.txt is an exclusion protocol (telling bots where not to go), while llms.txt is an invitation protocol (telling AI agents exactly where the "gold" is located). They should coexist.
Does this file improve my Google search ranking?
Currently, no. llms.txt is designed for generative AI agents and LLM context windows. It does not carry weight in Google’s traditional ranking algorithms, though it may improve your visibility in AI-powered search results (e.g., SearchGPT or Perplexity).
How often should I update my llms.txt file?
You should treat it as a living document. Update it whenever you release new documentation, change your core product architecture, or launch a significant feature that requires AI understanding.
Should I use llms.txt or llms-full.txt?
Use llms.txt as a high-level site map for general agents. Use llms-full.txt only if you have specific technical documentation, API specs, or knowledge bases that you want an AI to "memorize" instantly without needing to crawl your entire site.