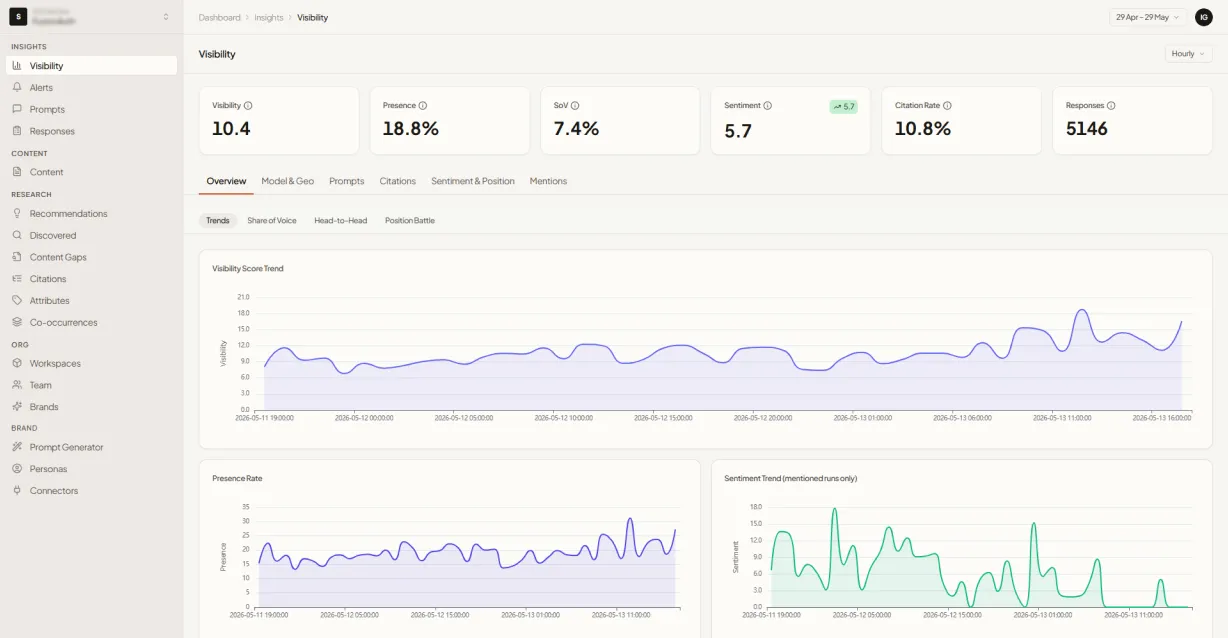
How a monitor run works
Five steps turn one question into a number you can trust
A monitor is not a keyword lookup. It asks a real buyer question, the way a buyer would ask it, then takes the answer apart. Here is the path every run follows before anything reaches your dashboard.
1
Ask
Send your prompt to the engine as a genuine buyer query.
2
Spread
Repeat across 10 engines, by persona and by region.
3
Capture
Store the whole answer word for word, not a summary.
4
Read
Pull six signals out of every answer automatically.
5
Compare
Check against history and alert you if something moved.
One prompt goes in. A stable, checked, comparable result comes out, every cycle.
The hard part we solved
The challenge is not asking a question once. It is asking it well, thousands of times a day, across engines that were never built to be measured. Most of them have no monitoring API, so we query them through the same surfaces a real person uses, while handling rate limits and session context so the answers stay representative.
The deeper problem is that language models are non-deterministic. Plainly put, ask the same question twice and the wording, the order of brands, even which sources get named can change. A single answer is closer to one response in a poll than a fact. So we run each prompt many times and combine the results. When your dashboard says you moved from second to fourth, it means the pattern shifted, not that one sample happened to wobble.