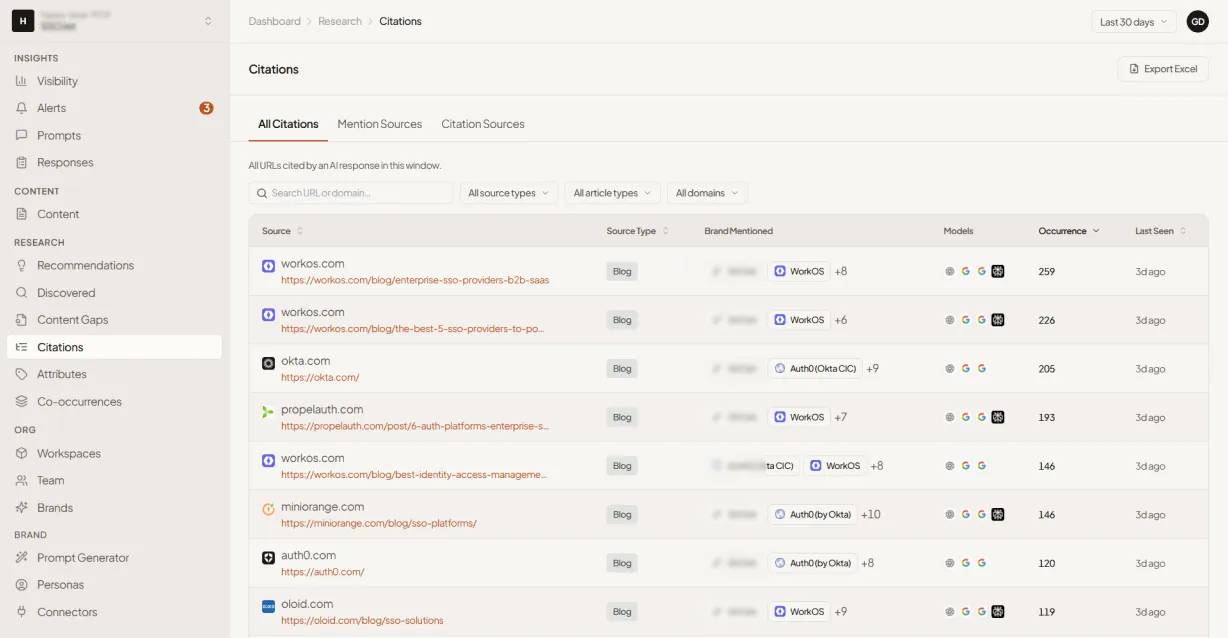
How the source map is built
Tracing every answer back to the pages that produced it
To map the sources behind your category, each answer is taken apart and followed upstream. The steps below turn a pile of replies into a ranked picture of which domains the engines actually rely on, and where you stand in each one.
1
Capture
Collect answers across engines and prompts in your category.
2
Extract
Find the sources, both the cited ones and the hidden ones.
3
Resolve
Group links into domains and source types.
4
Score
Rank domains by how much they shape the answers.
5
Map
Check where you appear, and where you are missing.
Scattered answers in. A ranked map of who feeds them, and where your gaps are, out.
The hard part we solved
Some engines make this easy. Perplexity, Copilot and Google's AI Overviews show their sources, so we read the citations directly. Others, like ChatGPT and Claude, often answer without showing their work. For those, we infer the likely sources by matching the specific claims, numbers and phrasing in an answer against the candidate pages on the open web that could have produced them.
That inference is closer to detective work than to scraping a link, and it is what keeps the map complete even when an engine hides its references. Without it, you would only ever see half the picture, and the half you missed could be exactly where a competitor is winning.